今天继续跟着demo学习。
data_fetch.py:
它是一个加密货币价格数据获取工具,可从以太坊链上获取ETH/USDC实时价格或生成模拟数据,为交易策略提供支持。
backtest.py
这个文件是一个回测系统,用来模拟交易策略在历史数据上的表现。
简单说就是:给你一个交易策略,它会在过去的价格数据上"虚拟交易",然后告诉你这个策略能赚多少钱、风险有多大、交易了多少次等详细统计信息。
utils.py
这个文件是一个工具函数库,提供了各种常用的数据处理和分析函数。
简单说就是:包含计算收益率、波动率、夏普比率等金融指标的函数,以及数据验证、格式化显示、配置管理等辅助功能,是整个项目的"工具箱"。
工具函数库名词解释
setup_logger
是一个日志设置函数。
简单说就是:它帮你创建一个日志记录器,可以自动记录程序运行时的信息(比如错误、警告、调试信息等),并且会显示时间戳和日志级别,方便你查看程序运行状态和排查问题。
def setup_logger(name: str, level: int = logging.INFO) -> logging.Logger:
"""设置日志记录器"""
logger = logging.getLogger(name)
logger.setLevel(level)
if not logger.handlers:
handler = logging.StreamHandler()
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
handler.setFormatter(formatter)
logger.addHandler(handler)
return logger
价格收益率

价格变化的百分比
基本概念
- 收益率 = (新价格 - 旧价格) / 旧价格 × 100%

举例说明
例子:股票
- 昨天股票价格:100元
- 今天股票价格:110元
- 收益率 = (110 - 100) / 100 = 10%

波动率
衡量资产价格在一定时期内波动程度的指标![]() ,反映了价格偏离其平均水平的幅度。
,反映了价格偏离其平均水平的幅度。
衡量市场的市场不确定性和风险相对较大
夏普比率
帮你算「收益性价比」的指标
核心意思:
它像一把尺子,衡量你承担的风险是否值得——收益越高 ![]() ,风险越低
,风险越低 ![]() ,夏普比率就越好。
,夏普比率就越好。
- 分子(收益):是你「赚的超额收益」—— 扣除无风险收益(比如存银行的利息)后,真正靠承担风险换来的利润
 这个数字越大,说明「回报」越诱人。
这个数字越大,说明「回报」越诱人。 - 分母(风险):是你「承担的波动」—— 收益上蹿下跳的幅度,代表了赚钱的不确定性
 这个数字越大,说明「付出的风险成本」越高。
这个数字越大,说明「付出的风险成本」越高。
两者确实存在「对抗感」:夏普比率的本质,就是用「超额收益」去「对冲」风险—— 只有当收益的增长跑赢风险的增长时,这个指标才会变好。就像你打工:薪水涨幅(分子)必须超过工作强度的增加(分母),这份工作才更「值」![]()
夏普比率 = (投资收益 - 无风险收益) ÷ 风险波动
最大回撤:投资路上的「最深坑」
简单说,就是你买的东西从最高点跌落到最低点时,亏得最惨的那一次。
它像个「风险警示灯」![]() :最大回撤越大,说明这东西曾经跌得越狠,你可能要做好「暂时被套牢」的心理准备;
:最大回撤越大,说明这东西曾经跌得越狠,你可能要做好「暂时被套牢」的心理准备;
反之,回撤小,说明它抗跌性比较强,波动没那么吓人。
买基金、股票前看看这个,就知道它历史上「最惨能亏多少」,心里有数才好下手~ ![]()
复合收益率:让钱「滚雪球」的速度 
收益再生收益
年化收益率:把「零散收益」拉成「全年进度条」
注意两个坑  :
:
- 它是「预期」不是「保证」—— 就像天气预报说今天 30℃,实际可能有点偏差

- 短期高收益≠全年都这样 —— 比如 7 天赚了 5%,年化可能高达 260%,但不可能一直这么赚
 →
→
一句话总结:
年化收益率像个「翻译官」![]() ,把不同时长的收益统一成「年单位」,让你一眼看出哪个更划算~
,把不同时长的收益统一成「年单位」,让你一眼看出哪个更划算~
合理的换算得带着「风险滤镜」来看,分享 3 个简单思路:
1. 先看「收益的稳定性」,给波动大的收益「打个折」 →
→
比如:
- 基金 A:1 个月涨了 10%,但每天涨跌像坐过山车(单日波动 ±8%)
- 基金 B:1 个月涨了 8%,但每天波动很小(单日 ±1%)
直接年化的话,A 是 120%,B 是 96%,看起来 A 更猛。但实际上,A 的收益是「赌出来的」,可能下个月就跌 20%;B 是「稳出来的」,更可能持续。这时候换算全年,得给 A 的高收益「打个风险折」(比如按波动幅度扣减),而 B 的收益更可信
—— 就像打工,忽高忽低的奖金(A)不如稳定的月薪(B)靠谱。
2. 拉长期限,看「穿越波动」后的真实收益 
短期收益(比如 1 个月、3 个月)可能刚好赶上「好时候」(比如市场突然大涨),没经历过下跌考验。想换算全年,不如看它「过去 1 年、3 年」的年化收益 —— 就像看一个人成绩,不能只看某次月考,得看期中 + 期末的平均成绩,更能反映真实水平。
比如:某基金 1 个月涨 15%(年化 180%),但过去 3 年年化只有 8%,说明短期是「昙花一现」,全年大概率回归 8% 左右,风险藏在后面呢。
3. 绑上「风险指标」一起算,比如「夏普比率」+「最大回撤」
光算「收益年化」是「裸奔」,加上风险指标才是「穿了铠甲」:
- 短期收益高,但夏普比率低(说明赚的钱靠冒大险)→ 换算全年时,得想到「高收益可能伴随高回撤」,实际到手可能远低于年化。
- 短期收益中等,但最大回撤小(说明跌得少)→ 换算全年时,这个收益更「抗造」,实现的可能性更高。
就像租房:月租低但经常断水断电(高风险),和月租稍高但水电稳定(低风险),后者的「实际居住体验」(真实收益)更好。
总结:
短期收益换算全年时,风险不是「额外选项」,而是「必答题」
![]() 与其纠结「怎么算准全年收益」,不如问自己:「这个短期收益,是靠运气还是实力?经不经得起跌?」—— 想明白这两个问题,比单纯换算数字更有用~
与其纠结「怎么算准全年收益」,不如问自己:「这个短期收益,是靠运气还是实力?经不经得起跌?」—— 想明白这两个问题,比单纯换算数字更有用~ ![]()
这些函数主要服务于回测系统 (backtest.py):
- 夏普比率 → 评估策略的收益风险比
- 最大回撤 → 评估策略的最大风险
- 收益率 → 基础计算函数
- 波动率 → 目前未使用,可能是为未来功能预留
对于预测比赛来说,这些函数可能不是必需的,因为目标是预测收益率,而不是评估交易策略的表现。但如果需要分析不同币种的风险特征,波动率函数可能会有用! ![]()
打算让curosr生成一个新的demo:
提示语:加密货币收益率排名预测 Demo 生成
任务描述生成一个 Python 脚本,模拟完成加密货币收益率排名预测任务,包含数据加载、特征工程、模型训练、预测和评估全流程。代码需使用随机数据模拟比赛环境,最终输出预测的加密货币收益率排名,并计算与 “真实” 排名的加权斯皮尔曼相关系数。
具体要求
- 数据模拟
- 生成包含 50 种加密货币、10 个特征的数据集
- 添加时间维度(如 30 天历史数据)
- 特征需包含价格、成交量、波动率等典型市场指标
- 特征工程
- 计算技术指标(如 MA5/MA10、RSI、MACD)
- 提取时间特征(周几、月周期等)
- 创建至少 5 个衍生特征
- 模型构建
- 使用集成学习模型(如 RandomForest/XGBoost)
- 实现交叉验证(至少 5 折)
- 包含超参数优化(如随机搜索)
- 预测与评估
- 预测未来 7 天的收益率
- 生成排名结果(按预测收益率降序)
- 计算加权斯皮尔曼相关系数(权重可设为市值或交易量)
- 代码结构
- 使用函数模块化设计(数据处理、模型训练、评估分开)
- 添加必要的注释和文档字符串
- 包含异常处理(如数据缺失、模型训练失败)
- 可视化
- 绘制特征重要性图
- 对比预测排名与实际排名的散点图
- 输出模型性能指标(如准确率、召回率)
这个demo需要python3.9版本,于是我选择使用anaconda。之前没用过,所以把步骤记录如下:
需要的可以看notion链接。
需要注意,这个demo中我使用了talib-binary,这是金融常用的库,pip安装屡屡失败,找到的解决方案是:
conda install -c quantopian ta-lib //需要已有anaconda
供大家参考。
后续安装依赖时,建议优先使用 conda 命令(如 conda install -r requirements.txt),确保环境一致性。
demo的输出:
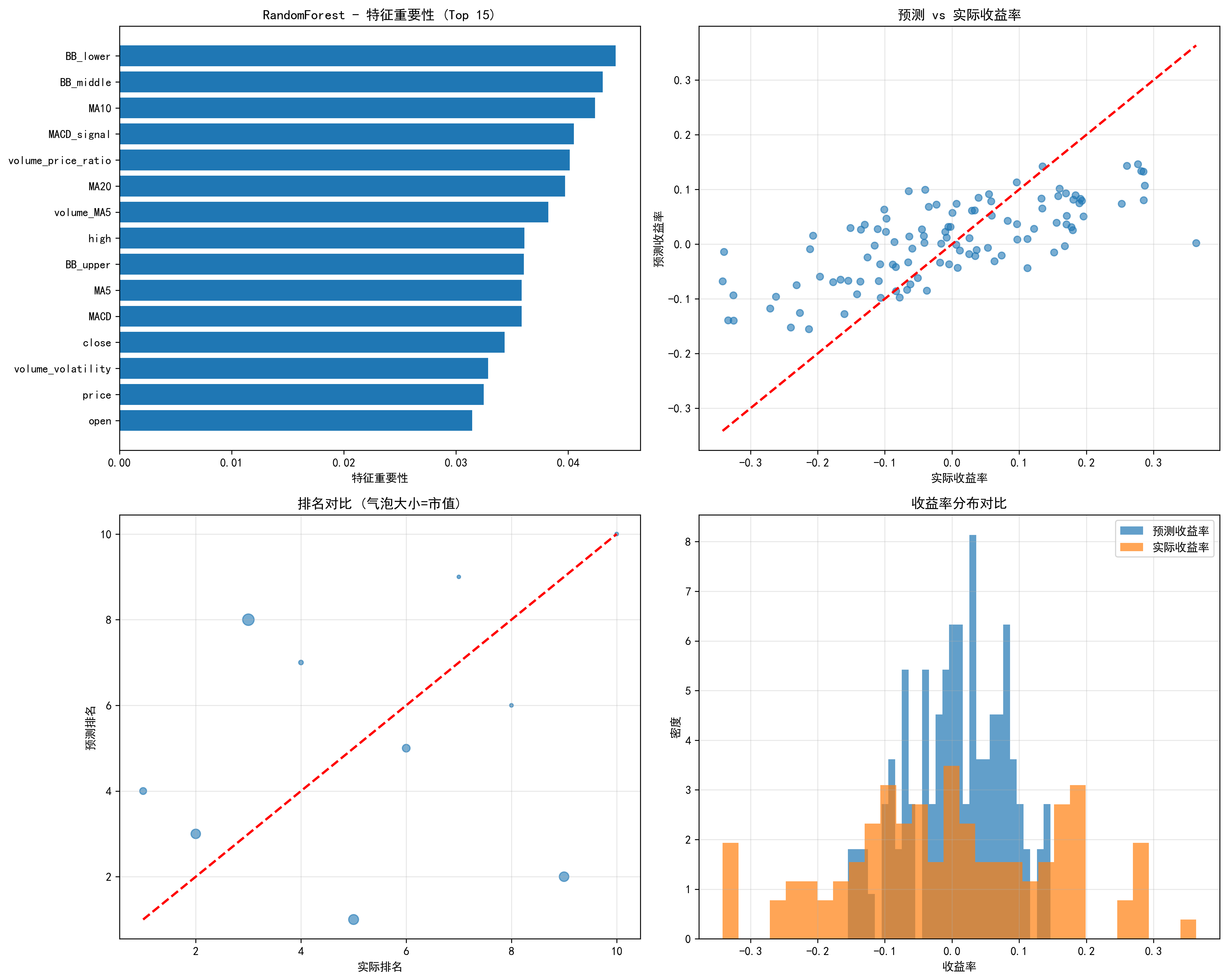
feature_engineering.py
这个文件基本上就是计算各种技术指标,相关的技术指标和昨天的内容基本重合。指标的计算方法是金融领域的”经典公式“,在代码中利用库实现,不是机器学习算法。
目前demo实现得是”标准做法“,没有用到创新得算法。主要是”工程创新“而不是”算法创新“。
model_training.py
这个文件是机器学习库。用feature_engineering输出的特征数据训练模型。
demo里完全调用的是现成的机器学习库,sklearn和xgboost,明天可以分别研究一下这两个库。
总结:
目前对比赛的想法是,先学现成的经典方法,再去kaggle看一下别人是怎么融合模型的,最后试试自己调参选择。
“算法创新”需要深入研究机器学习和深度学习,太难了。但是我们胜在人多,大家可以从不同方向攻破比赛。![]()