面向demo学习量化建模
这段描述提供了一个量化交易策略的核心思路。下面是对该策略的梳理和总结:
1. 数据加载与预处理
-
数据来自
/kaggle/input/avenir-hku-web/kline_data/train_data下的 Parquet 文件,每个文件包含单一币种的K线数据,字段包括时间戳、开盘价、最高价、最低价、收盘价和交易量等。 -
通过
get_all_symbol_list函数扫描文件目录,获取所有币种符号。 -
使用并行化的
get_single_symbol_kline_data函数读取各币种数据,并计算多个技术指标。 -
指标计算:VWAP、RSI、MACD、买卖量比率、VWAP偏离度、布林带宽度、ATR等。这些因子反映了价格趋势、波动性、交易活跃度等。
- VWAP:通过交易金额与交易量的比值计算,并用线性插值填补空缺。
- RSI 和 MACD:通过
ta库计算,分别用于捕捉超买超卖和趋势反转。 - 布林带宽度 和 ATR:反映价格波动范围和波动强度。
-
收盘价和交易量被限制在5%到95%的分位数范围内,以减少异常值的影响。
-
所有数据对齐到统一的15分钟时间轴,缺失时间点通过前向填充补全。
2. 因子计算与数据集构建
-
目标变量:基于VWAP计算24小时的收益率。
-
计算的因子:
- 波动率:7天的15分钟收益率标准差。
- 动量:VWAP的7天变化率。
- 交易量:7天的总交易量。
- RSI、MACD、布林带宽度、ATR等技术因子。
-
使用
stack方法将因子转化为长格式数据,并与目标变量合并为训练数据集。 -
使用
dropna去除空值,之后通过StandardScaler对特征进行标准化。
3. 模型训练与优化
-
采用 XGBoost回归模型 进行训练,设置了如下参数:
- 学习率:0.05
- 最大深度:6
- 子采样率:0.8
- 树木数量:200
- 早停:10次
-
加权斯皮尔曼相关系数:对高低10%收益率的样本加大权重,增强对极端值的预测。
-
时间序列交叉验证(5折)确保模型具有对时间趋势的鲁棒性。
-
通过对验证集上加权斯皮尔曼得分最高的模型进行选择。
-
预测结果经过 指数加权移动平均 平滑,减少噪声。
4. 提交文件生成
- 预测结果结合时间戳和币种符号生成ID列,ID格式为时间戳+币种符号,移除空格和特殊字符以符合提交格式。
- 读取
/kaggle/input/avenir-hku-web/submission_id.csv文件,确保提交文件包含所有要求的ID,缺失的ID使用0填充。 - 生成最终的
submit.csv(包含ID和预测收益率)和check.csv(包含真实收益率),并计算整体加权斯皮尔曼相关系数以评估模型性能。 - 提供调试信息,以监控数据丢失和格式问题。
5. 优化与改进
-
并行处理调整:将并行进程数量减少到2,以降低内存压力。
-
ID格式一致性检查和数据量监控(特别是在
dropna操作前后)。 -
优化点:
- 多时间尺度因子:结合短期和长期趋势,提升模型对市场动态的捕捉能力。
- 跨币种相关性分析:考虑不同币种之间的关系,增强模型的预测能力。
- 超参数调优:进一步优化模型性能。
6. 新修改内容:
-
PyTorch 加速:使用张量计算加速因子的计算,特别是在滚动窗口的 EMA(指数加权移动平均)计算上进行优化。
-
新增因子:
- 4小时动量:捕捉短期趋势。
- 24小时交易量动量:反映市场活跃度的变化。
- 买卖量差分:衡量买卖压力,替代原有的买卖量比率。
-
因子计算逻辑:
- 动量因子:通过VWAP的4小时和7天窗口平衡短期和长期趋势。
- 交易量因子:结合长期总量(df_amount_sum)和短期变化(df_vol_momentum)。
- 市场压力:通过买卖量差分(df_buy_pressure)替代买卖比率,直接反映市场不平衡。
-
SHAP分析:通过SHAP值分析评估因子的贡献,便于后续调整和优化因子选择。
总结:
该量化策略从数据处理到模型训练再到最终预测结果生成,采用了大量的技术指标和因子来捕捉市场的动态,并通过XGBoost回归模型进行训练与优化。最新的改进通过PyTorch加速计算,并引入了更多的短期和长期市场趋势指标,同时通过SHAP分析提升因子的可解释性和优化空间。
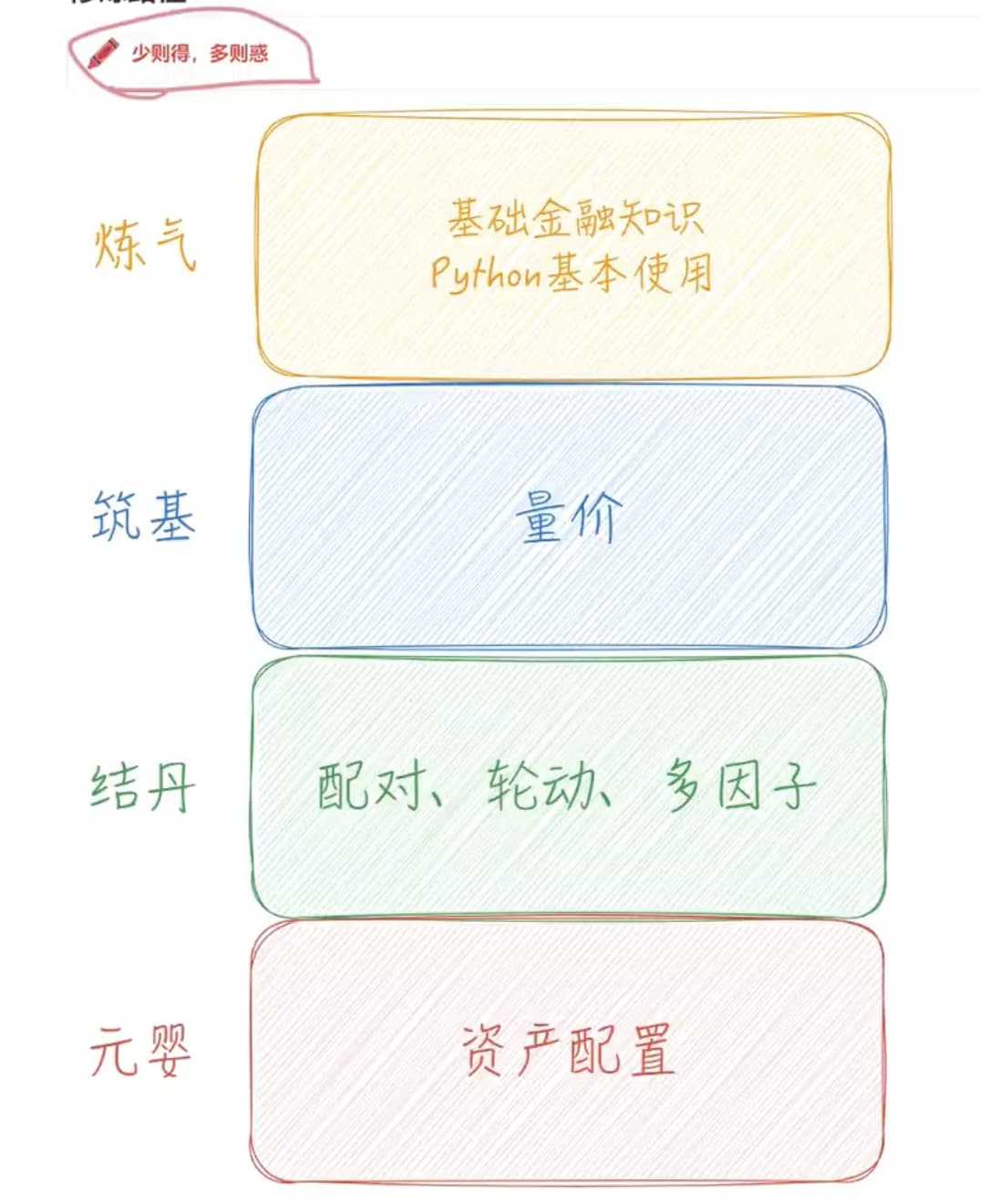
上图为b站up主提出的量化学习修仙论