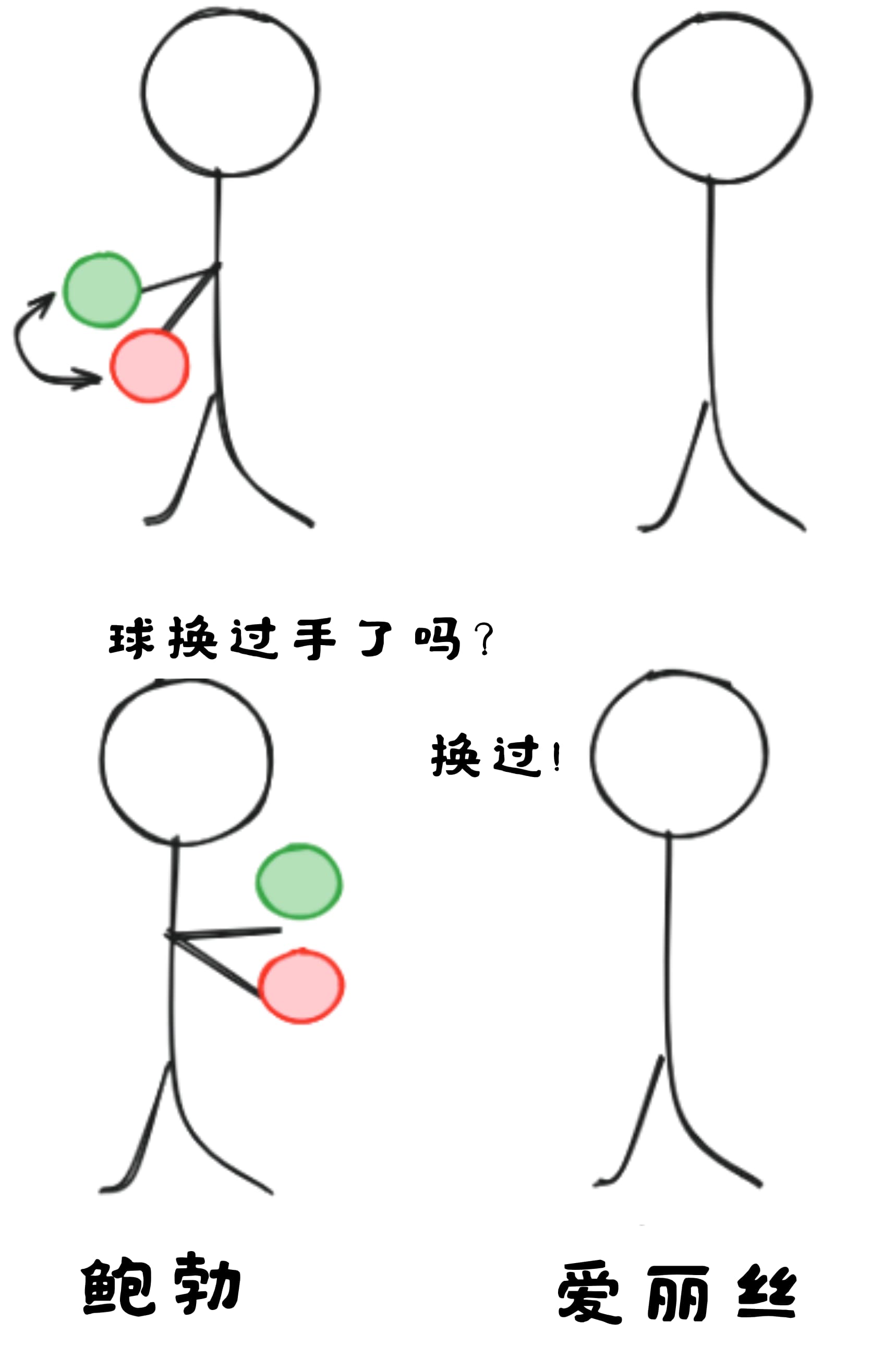
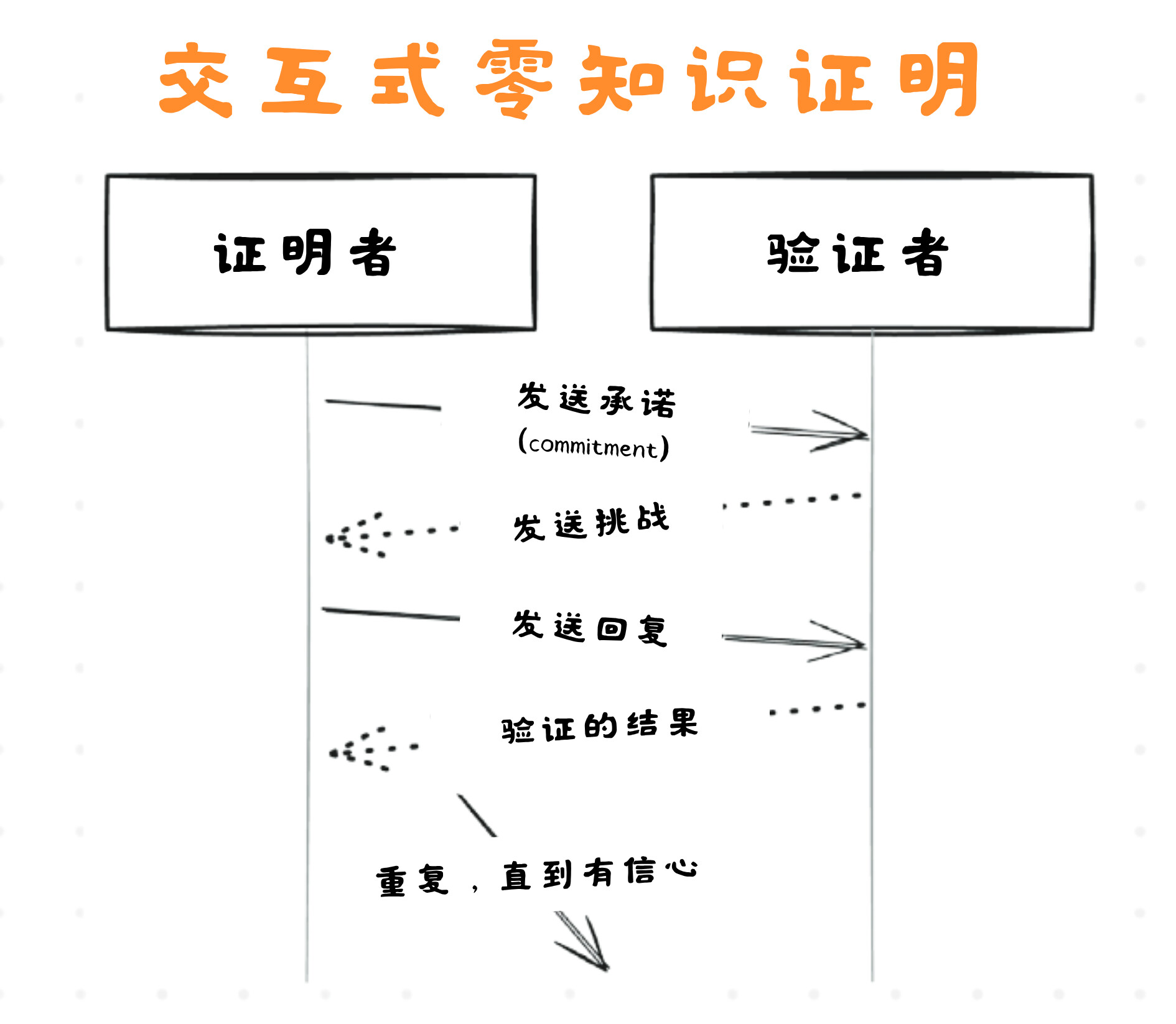
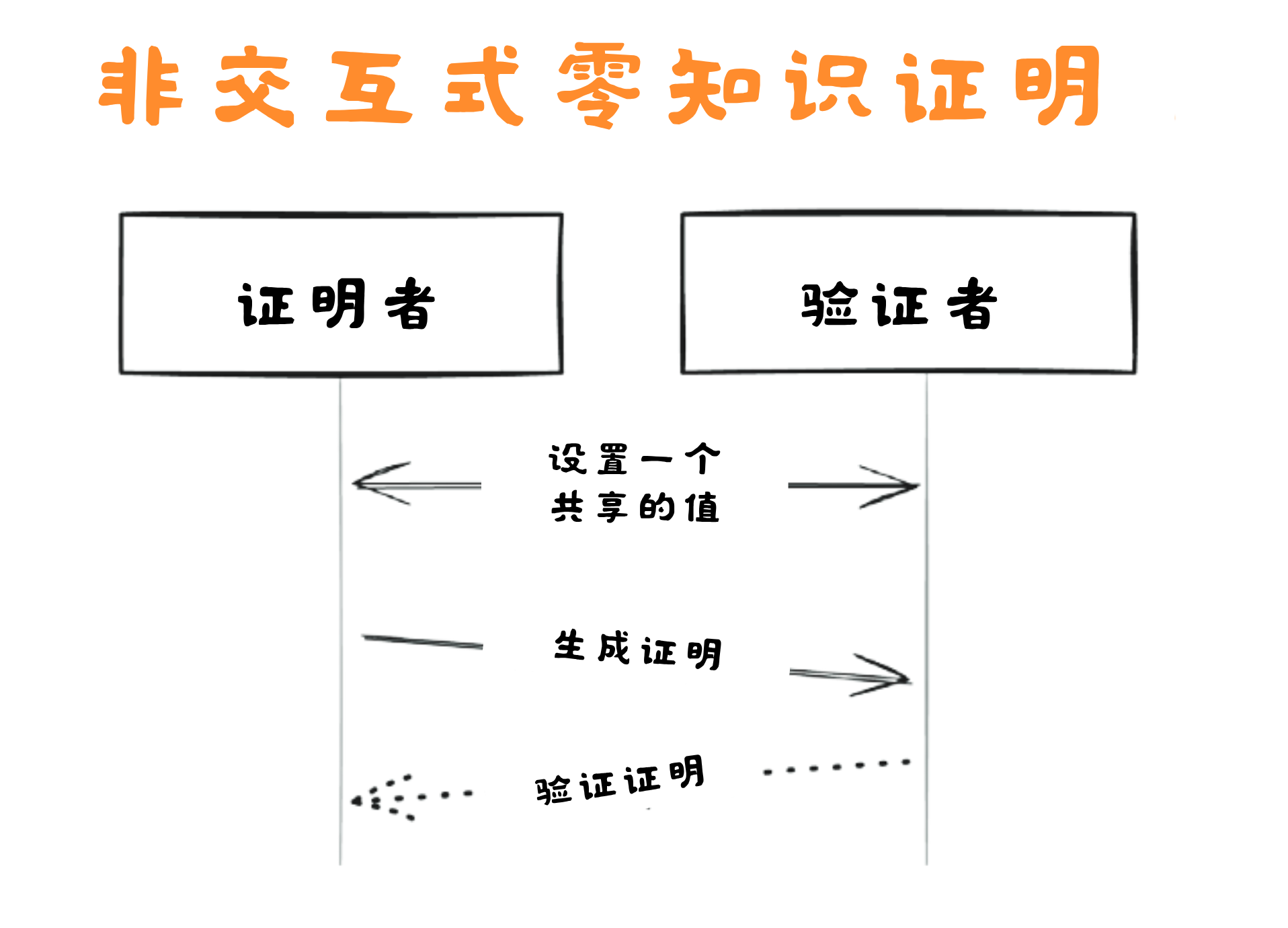
协议基础 001:密码学
Mario Havel 与 Tim Beiko
一
纵观历史,人类一直使用密码学(Cryptography)来保护敏感信息免受窃听。著名的例子是,为了避免依赖信使的忠诚度,朱利乌斯·恺撒(Julius Caesar)会对发送给前线将军的消息进行加密。他的具体做法是将原始消息中的每个字母替换为字母表中距离它固定位置的另一个字母。例如,通过使用3个偏移量,单词 ”attack“ 可被改为 “dwwdfn”:d 是 a 后面的第三个字母,w是t后面的第三个,以此类推。这种技术被称为恺撒密码(Caesar cipher)。只要凯撒事先与将军沟通好偏移量,他就能发送看似无法解读的消息,而将军们可以随后解密这些消息 [1]。
随着时间推移,出现了比凯撒密码更难逆向破解的密码。维吉尼亚密码(Vigenère cipher)就是一个例子。这种密码不再使用固定值替换每个字母,而是根据一个秘密代码词(称为密钥,key)的字母在字母表中的顺序,为每个字符设定不同的偏移量。例如,密钥 “abc“ 会将编码单词的第一个字母按字母表顺序偏移一个位置,第二个字母偏移两个位置,第三个字母偏移三个位置,分别对应字母 a、b、c 在字母表中的位置。如果输入信息比密钥长,则密钥会循环使用 [2]。
数学的进步催生了更复杂的加密技术。随着代数的出现,人们开始利用模运算(modular arithmetic)和指数运算(exponentiation)等原理,增加破译消息的难度。向数学密码学的转变为更精密的加密技术奠定了基础。最终,机器被用于提升密码的复杂程度,超越了人类可以直接计算的范围。德国在第二次世界大战期间依赖的(臭名昭著的)英格玛机(Enigma machine)就是这样一个例子 [3]。
虽然消息加密的具体方式各不相同且日益复杂,但从概念上讲,所有这些技术都采用了相同的设计:
使用密钥加密输入信息,与接收者共享密钥,接收者再用密钥解密信息。
这种发送者和接收者使用同一密钥的设计被称为对称密钥加密(symmetric-key encryption)[4]。
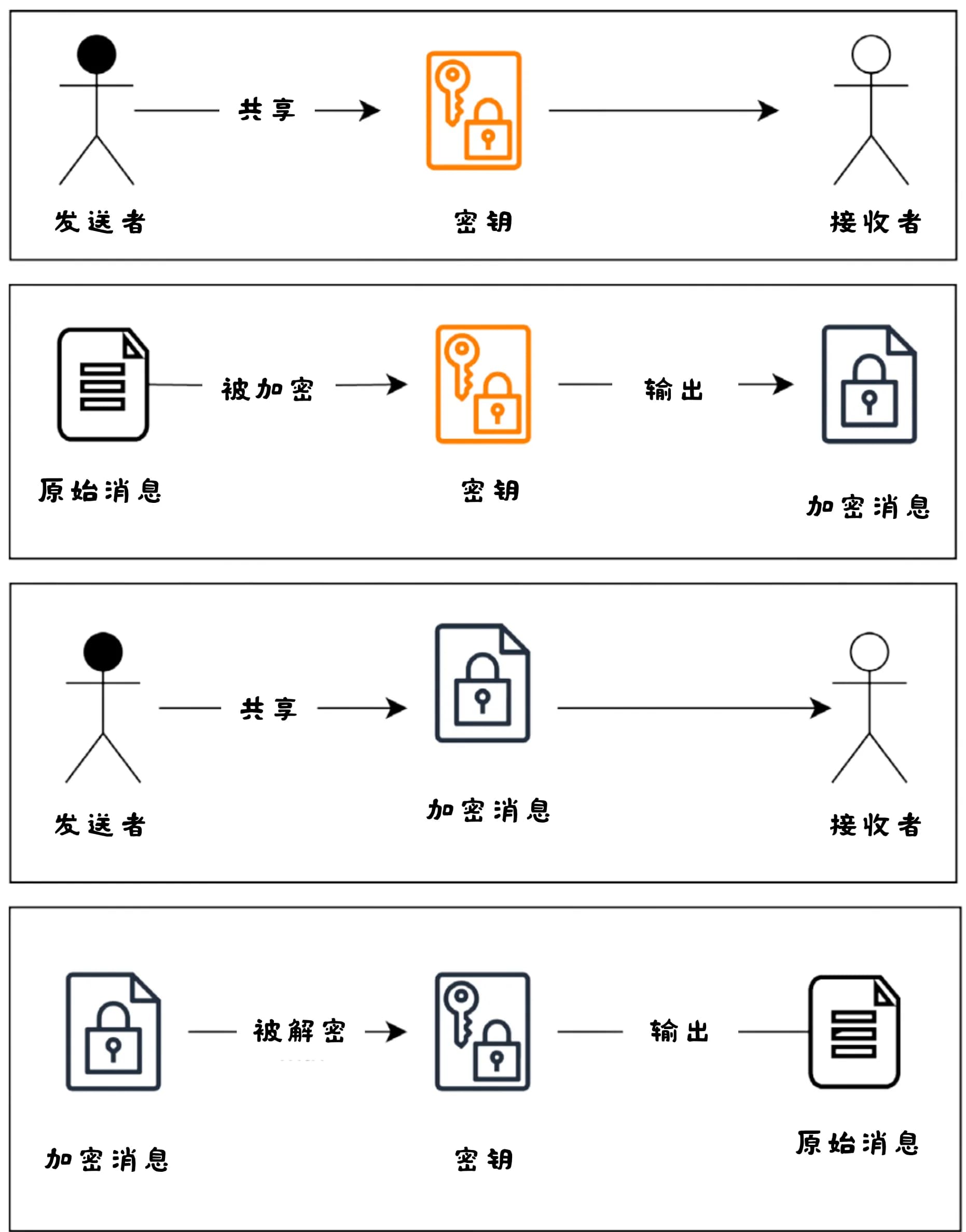
对称加密的最大缺陷在于其假设密钥可以被安全地传递给预期接收者,而不会泄露。换句话说,无论密钥是以单个数字、秘密单词,还是特定配置的机器的形式存在,都必须在可信环境中从发送方传递到接收方。所有后续消息的安全性都依赖于密钥的安全传输。
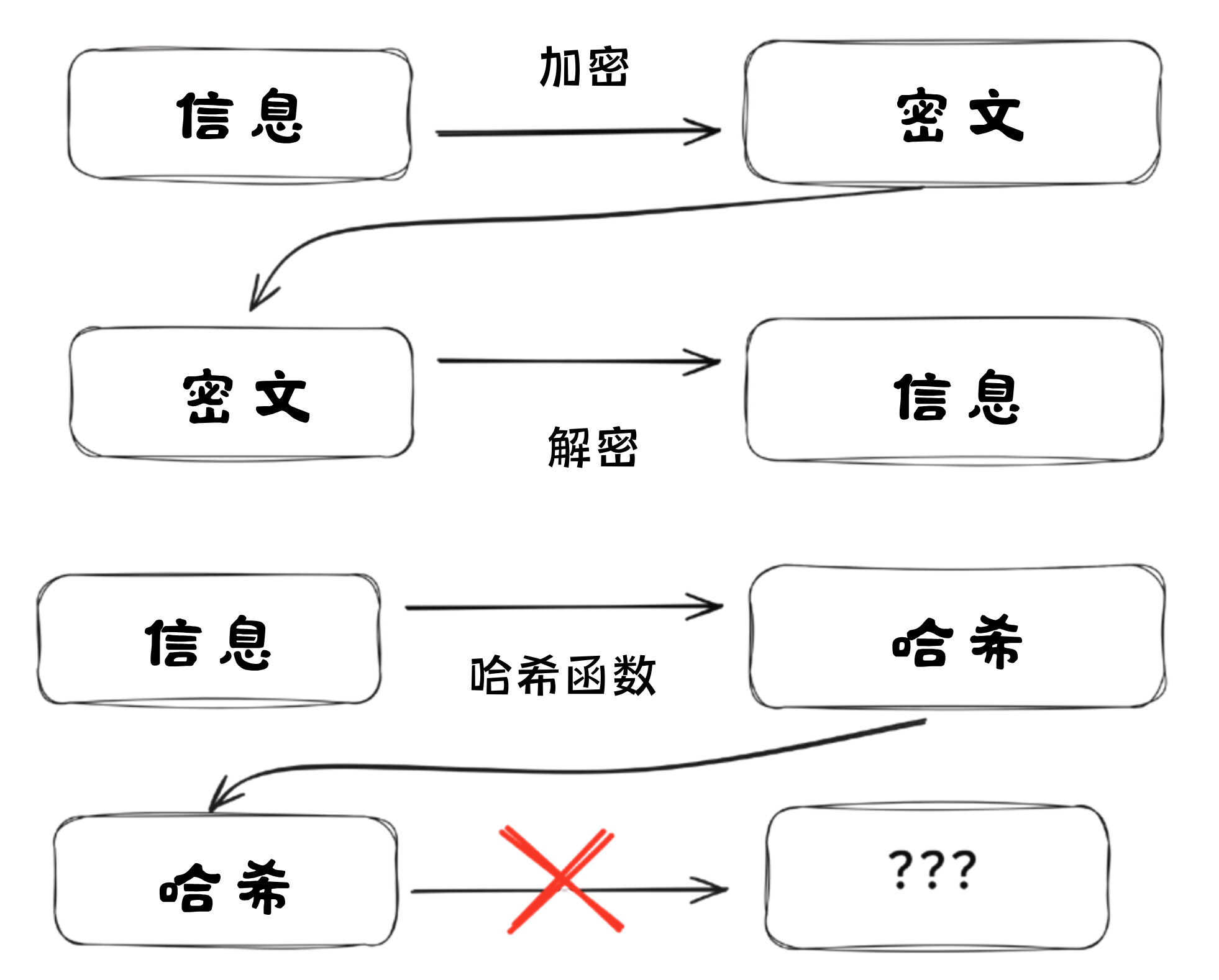
1976年,《密码学的新方向》(New Directions in Cryptography)[5] 提出了一种解决方案,为如今被视为现代密码学基础的技术奠定了基石:非对称加密(asymmetric encryption)。其概念突破在于从单一的共享密钥(对称密钥加密)转变为成对的密钥,即密钥对(keypair)。密钥对由私钥(private key)和公钥(public key)组成。
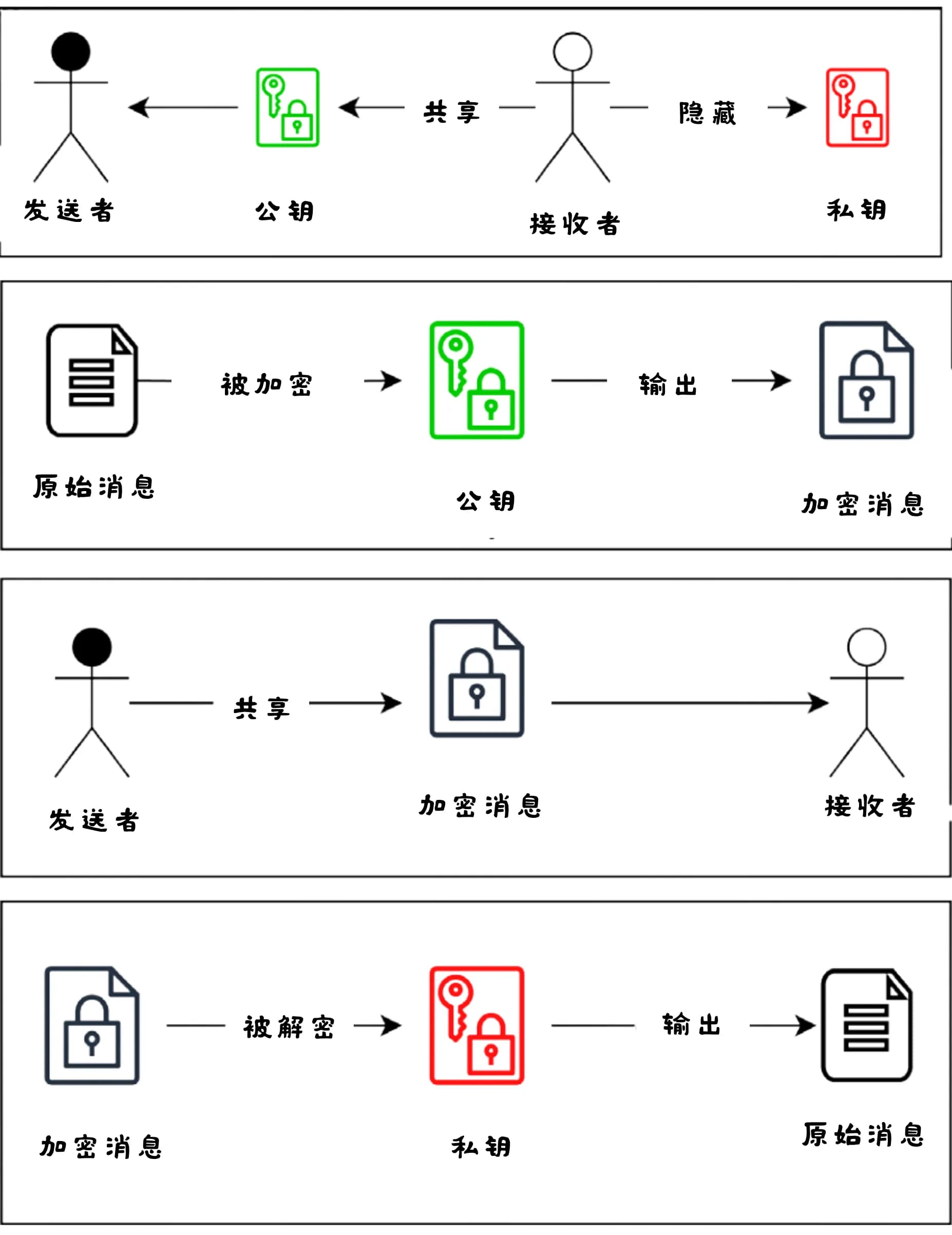
要加密一条消息,接收者首先生成一个私钥,这是一个很大的随机数。该数字必须范围足够大且随机,以确保无法被猜到——据说比宇宙中原子的数量还要多。然后以确定性方式从私钥生成公钥。公钥也是一个巨大的数字,但不会泄露私钥的信息。仅凭观察公钥,无法推测出生成它的私钥。
由于公钥是由私钥推导而来,且得益于加密算法的数学特性,使用公钥加密的消息总是且只能使用其对应的私钥解密。接收者可以安全地广泛公布公钥,任何人均可使用该公钥加密消息。而这些消息只能通过对应的私钥解密,私钥永远不需要共享。
这是密码学演进中一次微妙而深远的转变:
非对称加密允许任何人公开一个公钥,供他人用来以发送只有接收者能解密的消息。
可以把个人的上锁信箱看作是公钥和私钥的物理隐喻。任何人都可以往信箱里投递信件,但只有信箱的主人能够打开它并阅读其中消息。
二
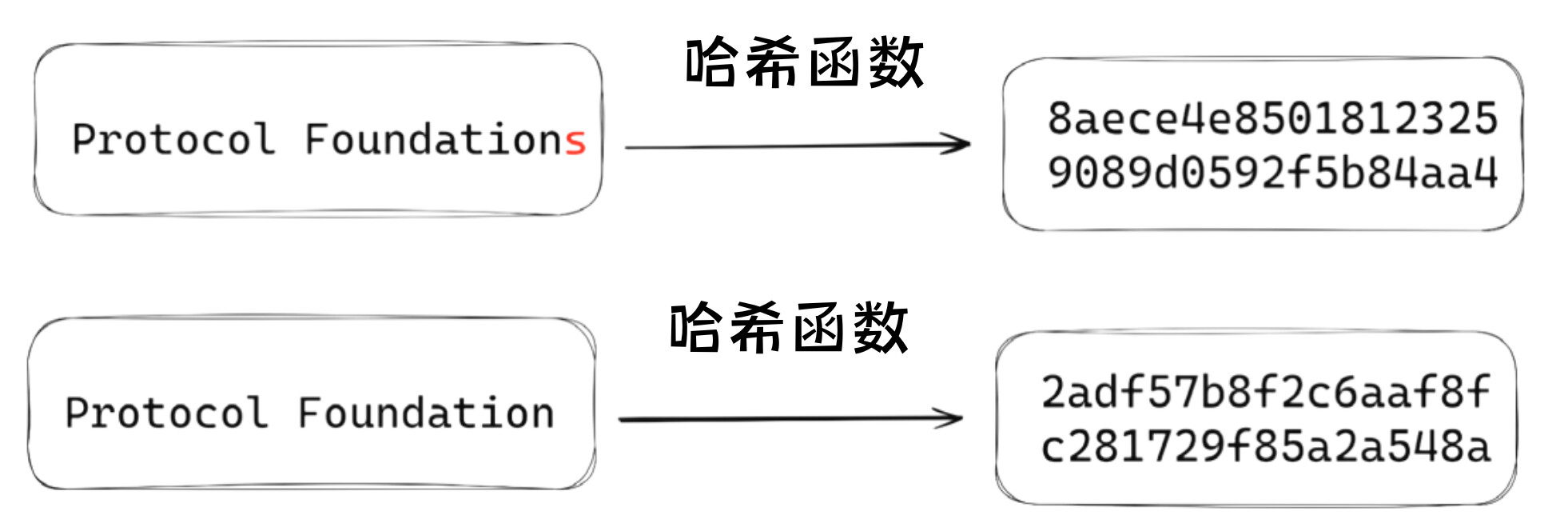
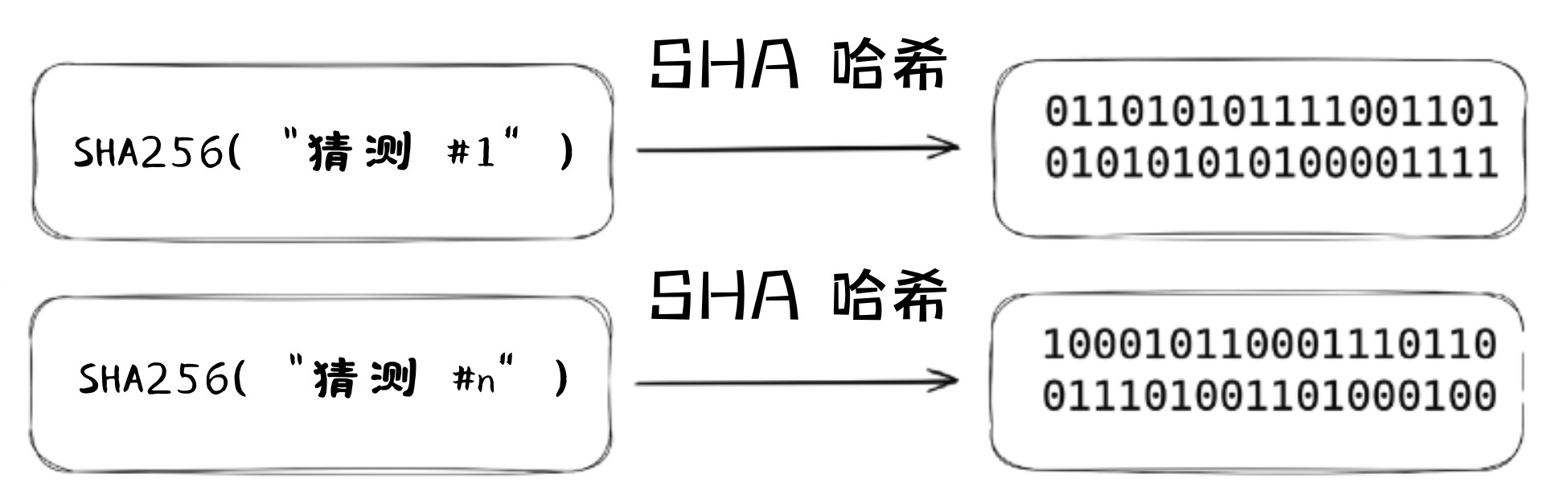
使用公钥进行安全加密只是非对称加密的一种可能性。私钥还可用于创建将任意数据与公钥关联的数学证明。这种证明被称为数字签名(digital signature),任何能够访问相关数据和对应公钥的人都可以验证其真实性 [6]。这种机制为个人和机构提供了通用标准,以评估在线数据的真实性。
加密和数字签名已成为现代通信的支柱。每当你连接到一个网站时,浏览器会使用 HTTPS 协议(https protocol)加密与网站服务器的所有通信 [7]。这确保了第三方(例如互联网服务提供商,ISPs)无法读取通信内容,从而得以安全传输敏感信息,如密码或支付数据。安全连接通过验证来自可信来源的签名证书(signed certificate)建立。该证书证明服务器确实属于您所连接的域名。
然而,并非所有安全和加密的通信方案都需要可信第三方。“很好的隐私”(Pretty Good Privacy, PGP)是最早且最被广泛采用的电子邮件加密示例之一 [8]。用户通过未加密的电子邮件分享其公钥,接收者随后可使用该公钥发送加密的回复。在这种情况下,没有中央权威机构验证密钥的有效性:发送者信任他们所持有的接收者公钥是正确的。
用户还可以通过个人网站或名片等方式主动公开他们的公钥(public key)。通过成员使用自己的密钥来为其他成员的密钥真实性建立证明,社区可以进一步建立信任网络(web of trust)。当然,用户仍需评估每个信任网络的可信度。
在如今的聊天时代,一个更新的实用安全通信示例是 Signal 协议(Signal protocol)。该协议在同名应用程序中实现,使用一种公钥形式,为一对一对一和多对多(群聊)的对话提供无缝用户体验。Signal 协议已成为低延迟加密通信的黄金标准,并被其他主流应用程序(如WhatsApp)采用。
尽管 Signal 和 WhatsApp 实现了相同的协议,但它们的实现方式截然不同。Signal 是一款自由与开源软件产品(free and open source software),任何人都可以审计其代码以验证实现的准确性。相比之下,WhatsApp的代码库完全是专有的(proprietary),用户无法依赖独立的公开审计者来审查其代码。他们只能信任应用程序开发者,确保代码没有无意的错误(bugs)或恶意的隐藏功能,如后门(backdoors,即允许外部方故意绕过加密以访问解密后(明文)的消息)。用户最敏感的信息可能在未经同意的情况下暴露给外部方的风险,正是密码学社区强烈倾向于开放性的原因。
一般用户可能永远不会阅读他们使用的应用程序的源代码,但安全研究人员能够进行审计,并由他人评估他们的结论,这降低了有意或无意错误的风险。审查代码的人越多,存在未被发现的错误的可能性就越低。
密码学起源于古代战争策略,如今已成为数字安全的基石。它是一门利用数学力量,创造遵循宇宙不变法则的系统的科学,以确保一个安全、互联的世界。
参考文献
[1] en.wikipedia.org/wiki/Caesar_cipher
[2] en.wikipedia.org/wiki/Vigenère_cipher
[3] en.wikipedia.org/wiki/Enigma_machine
[4] en.wikipedia.org/wiki/Symmetric-key_algorithm
[5] www-ee.stanford.edu/~hellman/publications/24.pdf
[6] en.wikipedia.org/wiki/Digital_signature
[7] en.wikipedia.org/wiki/HTTPS
[8] en.wikipedia.org/wiki/Pretty_Good_Privacy
关于作者
Mario Havel 和 Tim Beiko 是以太坊基金会协议支持团队的成员,该团队负责协助以太坊网络升级以及其他协议相关的倡议,包括“协议之夏”。
MARIO | github.com/taxmeifyoucan
TIM | warpcast.com/tim